FPGA中乘法器的加速运算
数字逻辑与系统设计设计报告
项目内容
题目:8位乘法器
实现的功能:
- 输入为两个8位有符号数或无符号数,输出16位相乘结果
- 采用Booth算法对乘法转化为部分和求和
- 采用Wallace算法减少部分和求和时所使用的全加器数量
编译器及测试仿真环境
win11系统,EDA环境为
Quartus,EDA软件版本为18.0,验证板卡为DE10Lite,波形仿真软件为Modelsim,软件版本为SE-64 2020.4
该8位乘法器设计特点
本文采用
Radix-4 Booth乘法器对乘法运算化简为4个部分和求和;同时对化简后的部分和采用Wallace树算法进行加速运算,减少全加器和半加器数量的使用。
Radix-4 Booth算法
Booth算法原理:
对于8位有符号数A可以表示为如(1)式所示,其中用$A_{i}$表示A的第$i$位:
$$
\begin{align}
A = -A_{7}\times 2^{7} + \sum_{i=0}^{6} A_{i} \times 2^{i}
\end{align}
$$
同时考虑对$A_{i}$进行如下分解:
$$
\begin{align}
A_{i} = A_{i} \times ( 2^{i+1} - 2\times 2^{i } )
\end{align}
$$
进而可以对8位有符号数A进行如下分解,补充定义$A_{-1}=0$得:
$$
\begin{align}
A =& -A_{7}\times 2^{7} + \sum_{i=0}^{6} A_{i} \times 2^{i} \notag\
=& -A_{7} \cdot 2^{7} + A_{6} \cdot 2^{6} + A_{5} \cdot ( 2^{6} - 2 2^{4} ) \notag\
& + A_{4} \cdot ( 2^{5} - 2\times 2^{3} ) + … + A_{0} \cdot 2^{0} \notag\
=& (-2A_{7} + A_{6} + A_{5})\cdot 2^{6} + (-2A_{5} + A_{4} + A_{3})\cdot 2^{4} \notag\
&+ (-2A_{3} + A_{2} + A_{1})\cdot 2^{2} + (-2A_{1} + A_{0} + A_{-1})\cdot 2^{0} \notag\
=& Coef_{3}\cdot 2^{6} + Coef_{2}\cdot 2^{4} + Coef_{1}\cdot 2^{2} + Coef_{0}\cdot 2^{0} \
\end{align}
$$
因此$A\times B$可表示如下式所示:
$$
\begin{align}
A\times B=&Coef_{3}\cdot 2^{6}\times B + Coef_{2}\cdot 2^{4}\times B \notag\
&+ Coef_{1}\cdot 2^{2}\times B + Coef_{0}\cdot 2^{0}\times B
\end{align}
$$
可以发现$2^{i},i=0,2,4,6$前的系数是由$A_{i},A_{i+1},A_{i+1}$构成的形式相近的式子,不妨记为$Coef$,故$Coef$与$A_{i}$,$A_{i+1}$,$A_{i+1}$满足的关系如下表所示:
| $A_{i+1}$ | $A_{i}$ | $A_{i-1}$ | $Coef$ |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 1 |
| 0 | 1 | 1 | 2 |
| 1 | 0 | 0 | -2 |
| 1 | 0 | 1 | -1 |
| 1 | 1 | 0 | -1 |
| 1 | 1 | 1 | 0 |
故可以将两个8位有符号数A,B的乘积$A\times B$转变为4个部分和的形式,实现计算量和资源使用量的减少。同时$Coef$的系数是有限的,故我们可以将$Coef$对应的操作按如下方式使用寄存器提前存储。
1 | p <= 16'd0; |
同时定义RSTn和done信号用于表征乘法运算的开始和结束,同时利用case语句实现对4个部分和的逐次表征,并利用多个$if$语句实现对$Coef$的判断进而实现对部分和形式的确定。
1 | module booth_multiply#( |
仿真测试与波形查看
- testbench代码撰写如下:
1 | //注若要完整运行所有结果,至少运行1400ns |
同时仿真波形如下图1所示:

同时如果检测该乘法器对所有8位有符号数相乘的可行性,则上述在testbench中手动设置乘数和被乘数的方法则会过于麻烦,因此也可以考虑如下方法来设置随机数仿真。
- 随机数型乘法器仿真testbench代码可补充如下:
1 |
|
但verilog中的随机数生成依赖于其中的种子seed,故我们可以直接利用乘数A的值做为下一次random生成所需的种子,这样我们就可以不用每次仿真调整随机数了,为我们测试乘法器的可靠性和鲁棒性带来方便。即将initial begin里的语句改成如下所示即可:
1 | initial begin |
同时仿真波形如下图2-图3所示:

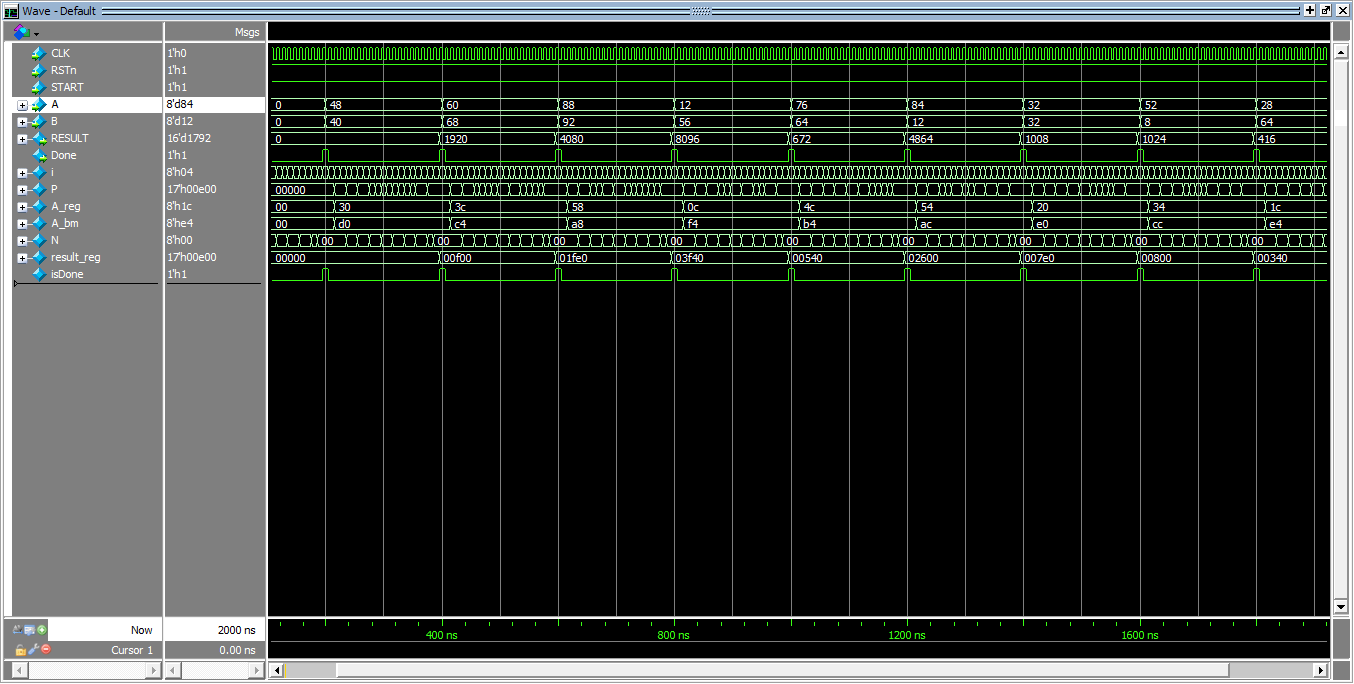
Wallace算法
本文采用Wallace算法实现对8位无符号数乘法器的加速,实现了部分和求和时所使用的全加器数量的减少。
全加器与半加器:全加器是一个三输入两输出的逻辑单元,它可以同时处理两个数据输入位以及一个来自前一级的进位输入,并产生一个本级的和输出以及一个向后一级传递的进位输出。而半加器仅处理两个数据输入位而不考虑前一级的进位,因此它的结构相对简单。
对于8位无符号数相乘,会出现8个部分积,故我们采用4:2压缩器,将其先压缩为4个部分积,再压缩为2个部分积
1 | //定义16位部分积的4:2压缩器 |
1 | module( |